He should be judged by attributes a midfielder should be judged on.
On those notes, as you said he is unspectacular.
He’s a b2b midfielder though so yes he should be judged on goal contribution.
He scores enough goals as a B2B midfielder.
He scored 4 last season being in and out of team, scored 10 the season previous.
xG is a bullshit stat anyway.
1 Like
He had 6 the season before last.
1 Like
Why?
Ramsey in 13/14 was just a god, 16 goals in 34 games for a central midfielder Non penalty taker  , also scored some worldie’s in that.
, also scored some worldie’s in that.
- Different outlet take different parameter into consideration. So if you align your thoughts as per one methology but the tweet made above was created by losing or adding parameters, the final value & your thoughts are not aligned.
http://www.scisports.com/news/2016/expected-goals-model-an-alternative-approach
-
Most of them use Machine Learning algorithm which needs supervised learning dataset before it can deliver right results as per parameters defined. But then you also need to account for formation change, positional change, personnel change; which is way too much inputs for any algorithm and eventually get regularized.
Check out regularisation in machine learning. -
Subtracting Expected goals and actual goals is not a one to one subtraction.
For example :
This goal by Alexis against Cologne
https://streamable.com/syhuq
That instance if taken into isolation, expected goal would have done well. Because of distance from goal, proximity of defender, Expected goal would have been 0. But Alexis defied the odds and scored.
So Goal - Expected Goal = 1
Which is right answer.
However Expected goal is calculated for entire match, and say the prediction is of 1.
Then Goal - Expected Goal = 0
Now the argument would be that in a way, the result is correct. Algorithm said one goal in a match and Alexis did the same; but check the below formula.
What this does is take into account every chance created for said player in previous matches and corrects itself. No player is going to make all the runs & recreate same chances as previous in a new match.
The goal predicted was far from goal actually scored.

Now post Cologne match, The algorithm is trained again and now Alexis xG map will have him better placed for long shots from that range, pushing his xG higher for next match. There is no guarantee that he is going to score similar goal again, so the algorithm is trained with a data which is not a norm.
-
Set Pieces
The formula used has a correction factor for setpieces. If Lacazette is not playing Sanchez will take the penalty and depending on whether he scores or not; his prediction for next match is modified.
But if Lacazette starts, he will take over the setpiece duty. So Sanchez’s stats are needlessly penalized or accentuated for a parameter he is not eligible for. -
Positional bias
The xG map is modified after every match.
Theo Walcott starts mostly on right so his map will be right biased; but if the injury crisis demands him to play on left, What will the algorithm do?
Work on existing dataset? or predict on non-existent dataset? or check unfilled left side & perdict 0 xG??
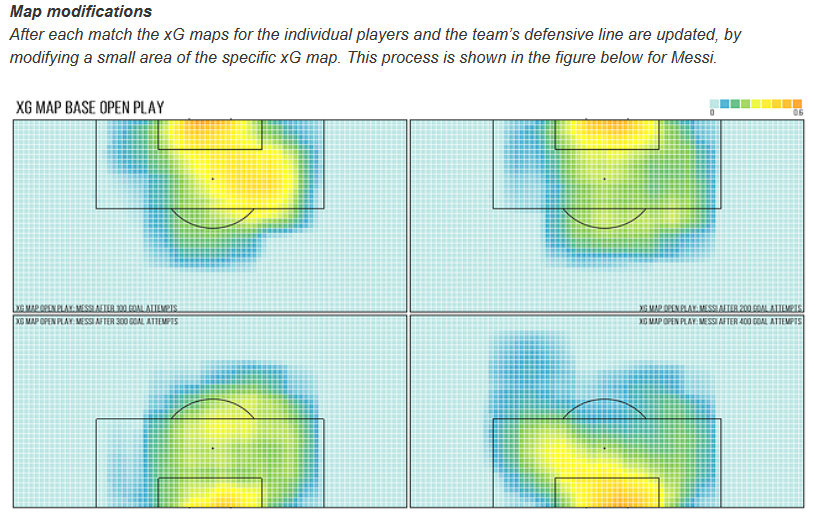
Change of position means change of runs & chance created.
If Aguero’s dataset was trained for the times he was a lone striker but the prediction is being made when he is sharing the strike with Jesus. The xG will be based on different scenario.
Since the audience always see basic numbers, the stat gets away with it.
11 Likes

Favorite ramsey goal from 13/14?
I’d probably say the one against Liverpool at the Emirates, yourself ?
2 Likes
Difficult choice but Norwich away
1 Like
Disclaimer : I have only recently started studying about these algorithms. More sophisticated approaches are available, so I could be completely wrong.
But I wanna be a hipster here. xG is bull.
Believing in xg is hipster, we’re just crotchety old men who don’t understand. 
Nah you’re not wrong, It’s peoples’ opinions coded into a program, it is subjective and makes for poor statistics. I’m sure the people who create xG crap know that ultimately it is just a broad attempt at quantifying, say, efficiency but then they toss it out and people who don’t understand it use it in arguments as if it carries heavy scientific value even though it is basically like saying “well some dudes somewhere agree/disagree with me”.
1 Like
Cup final
1 Like
“Box-to-Box”
Shit footballer.
How else do you define a midfielder that can’t defend and can’t score?
2 Likes
Useless, shite, wasteman?